#1 - 2019-4-14 10:25
流哲不哼太 (什么都看,什么都不懂)
角川家图片质量最好的电子版在这里卖,手上一堆自购书但是想要分享却只能截图。
已知有基于PC客户端的epub破解DRM方法,但知道的图源大佬们都表示不外传……
很苦恼,所以想请教一下诸位有能man。
已知有基于PC客户端的epub破解DRM方法,但知道的图源大佬们都表示不外传……
很苦恼,所以想请教一下诸位有能man。
顺序
#3 - 2019-4-14 17:18
bangumi 教宗

#3-1 - 2019-4-14 17:58
烈之斩
UUID就是每本书的ID,就在contents目录下
……但是这个工具最大的问题是,现在的bookwalker的客户端已经不会生成bwdb.sdf 倒是有个database.sdf
倒是有个database.sdf
我发你个我的文件夹你试试?
……但是这个工具最大的问题是,现在的bookwalker的客户端已经不会生成bwdb.sdf
倒是有个database.sdf我发你个我的文件夹你试试?
#3-2 - 2019-4-14 18:13
bangumi 教宗
明人不说暗话,懒得折腾(
你试直接把database.sdf 改成bwdb.sdf试试?
这个sdf文件应该是SQL server CE(类似SQLite)的数据库文件,用对应的driver就能读取
压缩包里有源码,我看了看,大概就是读取这个sdf文件,拿到密钥,然后把content文件夹的内容解密出来。
如果加密方法没变,可能需要的也就是改一改对应的数据库表名和字段名,应该也不会很难,但是这个工具是用c#写的,我并不会。
烈之斩 说: UUID就是每本书的ID,就在contents目录下
……但是这个工具最大的问题是,现在的bookwalker的客户端已经不会生成bwdb.sdf 倒是有个database.sdf
我发你个我的文...
你试直接把database.sdf 改成bwdb.sdf试试?
这个sdf文件应该是SQL server CE(类似SQLite)的数据库文件,用对应的driver就能读取
压缩包里有源码,我看了看,大概就是读取这个sdf文件,拿到密钥,然后把content文件夹的内容解密出来。
如果加密方法没变,可能需要的也就是改一改对应的数据库表名和字段名,应该也不会很难,但是这个工具是用c#写的,我并不会。
#3-3 - 2019-4-14 18:27
烈之斩
改名试过了,不行,会报数据库密码错误
我倒是找了个老的bwdb.sdf(我不知道为啥在程序的安装目录里有一份),能跑起来
但是所有图片解码都报“无法xxx到实例”之类的错误
我VS调试下看看吧……虽然不抱什么希望(其实之前就下到过这个工具,当时就没搞成功)
Trim21 说: 明人不说暗话,懒得折腾(
你试直接把database.sdf 改成bwdb.sdf试试?
这个sdf文件应该是SQL server CE(类似SQLite)的数据库文件,用对应的driver就能读...
我倒是找了个老的bwdb.sdf(我不知道为啥在程序的安装目录里有一份),能跑起来
但是所有图片解码都报“无法xxx到实例”之类的错误
我VS调试下看看吧……虽然不抱什么希望
(其实之前就下到过这个工具,当时就没搞成功)#3-4 - 2019-4-14 18:32
bangumi 教宗
看了看源码,研究了一下这个工具是怎么工作的,可能对你有一点帮助
作者用https://www.jetbrains.com/decompiler/ 反编译了bookwalker客户端(\BOOK☆WALKER\BOOK☆WALKER for Windows\bookwalker-cleaned.exe),然后拿到了用来解密的Class16(在class16.cs)中.(怪不得这个程序是c#写的)
这个bwdb.sdf是加密的,原本的密码是ccs3319_bookwalker(不知所措作者从哪弄出来的,但是他用base64转码过之后放倒了代码里)
然后从system_info读取了client_key_public和client_key_secret,client_uuid
从book表读取了解密用到的XOR_PHRASE
然后把这些传递给class16用来解密文件
如果加密方式改了的话,可能需要重新反编译看看加密的办法...
烈之斩 说: 改名试过了,不行,会报数据库密码错误
我倒是找了个老的bwdb.sdf(我不知道为啥在程序的安装目录里有一份),能跑起来
但是所有图片解码都报“无法xxx到实例”之类的错误
我VS调试下看看吧……虽...
作者用https://www.jetbrains.com/decompiler/ 反编译了bookwalker客户端(\BOOK☆WALKER\BOOK☆WALKER for Windows\bookwalker-cleaned.exe),然后拿到了用来解密的Class16(在class16.cs)中.(怪不得这个程序是c#写的)
这个bwdb.sdf是加密的,原本的密码是ccs3319_bookwalker(不知所措作者从哪弄出来的,但是他用base64转码过之后放倒了代码里)
然后从system_info读取了client_key_public和client_key_secret,client_uuid
从book表读取了解密用到的XOR_PHRASE
然后把这些传递给class16用来解密文件
如果加密方式改了的话,可能需要重新反编译看看加密的办法...
#3-5 - 2019-4-14 19:23
ouoω
擦 jb還有這東西
Trim21 说: 看了看源码,研究了一下这个工具是怎么工作的,可能对你有一点帮助
作者用https://www.jetbrains.com/decompiler/ 反编译了bookwalker客户端(\BOOK☆WA...
#3-6 - 2019-4-17 17:00
流哲不哼太
这个工具我也找到过,也曾经想试试用旧版PC客户端行不行,可惜找不到旧版的安装包了。
烈之斩 说: UUID就是每本书的ID,就在contents目录下
……但是这个工具最大的问题是,现在的bookwalker的客户端已经不会生成bwdb.sdf 倒是有个database.sdf
我发你个我的文...
#3-7 - 2019-4-18 00:36
#3-8 - 2019-4-18 16:29
bangumi 教宗
程序用Dotfuscator加了壳, 我脱不掉,看不到加壳前的源码
没猜错的话密码应该在KReader.Model.Entity.CustomUri里面,这个cusmosUri里面应该就包含了密码的原文.
但我找不到什么办法看到他
烈之斩 说: 我在4chan看到有人破解过新版数据库的密码,可惜他已经删掉了。
没猜错的话密码应该在KReader.Model.Entity.CustomUri里面,这个cusmosUri里面应该就包含了密码的原文.
但我找不到什么办法看到他
#3-9 - 2019-5-6 21:47
Tandy1000
没想到这个帖子有大佬回复了,我之前搜索的时候还没有……这回感觉有希望了
我之前看那个4chan帖子的时候也下载了那作者发布的破解工具,结果下到最新版客户端以后发现下载的书籍已经不是bwdb格式了,直接改扩展名不可行。我后来是找到了一个2015年左右的老客户端,但是打开之后它会强制要求更新客户端版本然后自动退出,这就没办法下载书籍了……我不懂编程,当时在想要是有办法去掉里面强制要求更新的代码,或者替换其搜索更新版客户端的URL,是不是就能绕过强制更新检测了?可惜我完全不懂,这事也就搁置了……
就刚才我在谷歌搜索的时候也看到轻之国度的一个用户属性页缓存:
我知道我的请求很无耻,但我还是要说——可不可以把DAL安可4的权限降下来,我知道扫图和翻译的大大们贡献都很大,我们这些伸手党确实不应该说什么,我本人虽然日 ... 权限我已经压的很低了。协助我扫图的人本来是建议我加八九十的权限的。因为这种扫图方式是破解BOOK WALKER的客户端,源文件传播太多的话日方就会对此有所对策。因此这种扫图的权限都会比较高,也是实属无奈之举。而这种担忧在最近也变成了现实,最近一次BOOK WALKER客户端的强制更新似乎已经封住了这个后门,暂时无法破解了。你的情况来看,我建议你利用业 ... ...
这段话是2015年的留言,看来官方应该也是注意到了这个BUG然后强制更新封掉了……
等待各位大佬的研究成果中,非常感谢!
流哲不哼太 说: 这个工具我也找到过,也曾经想试试用旧版PC客户端行不行,可惜找不到旧版的安装包了。
我之前看那个4chan帖子的时候也下载了那作者发布的破解工具,结果下到最新版客户端以后发现下载的书籍已经不是bwdb格式了,直接改扩展名不可行。我后来是找到了一个2015年左右的老客户端,但是打开之后它会强制要求更新客户端版本然后自动退出,这就没办法下载书籍了……我不懂编程,当时在想要是有办法去掉里面强制要求更新的代码,或者替换其搜索更新版客户端的URL,是不是就能绕过强制更新检测了?可惜我完全不懂,这事也就搁置了……
就刚才我在谷歌搜索的时候也看到轻之国度的一个用户属性页缓存:
我知道我的请求很无耻,但我还是要说——可不可以把DAL安可4的权限降下来,我知道扫图和翻译的大大们贡献都很大,我们这些伸手党确实不应该说什么,我本人虽然日 ... 权限我已经压的很低了。协助我扫图的人本来是建议我加八九十的权限的。因为这种扫图方式是破解BOOK WALKER的客户端,源文件传播太多的话日方就会对此有所对策。因此这种扫图的权限都会比较高,也是实属无奈之举。而这种担忧在最近也变成了现实,最近一次BOOK WALKER客户端的强制更新似乎已经封住了这个后门,暂时无法破解了。你的情况来看,我建议你利用业 ... ...
这段话是2015年的留言,看来官方应该也是注意到了这个BUG然后强制更新封掉了……
等待各位大佬的研究成果中,非常感谢!

#9 - 2019-5-6 21:50
Tandy1000
#9-1 - 2019-5-10 03:55
烈之斩
萌享那个贴我看了下没啥下文(至少没人贴出来)。
4chan你搜18、19年的帖子就知道破解方法一直是有人有的(包括新版),包括国内也有很多人会,但是他们不外放而已(原因显而易见)。
其实BW的客户端加密也没怎么大改,就是数据库改了个名字换了个密码,我甚至怀疑图片加密的算法都没改。
4chan你搜18、19年的帖子就知道破解方法一直是有人有的(包括新版),包括国内也有很多人会,但是他们不外放而已(原因显而易见)。
其实BW的客户端加密也没怎么大改,就是数据库改了个名字换了个密码,我甚至怀疑图片加密的算法都没改。
#9-2 - 2019-5-10 09:55
Tandy1000
刚在外网搜的时候找到一个相关的脚本:
https://gist.github.com/Sg4Dylan ... 0-1-8_2018-02-09-js
然后在一个最近的帖子(http://cncc.bingj.com/cache.aspx ... 5UqM2Q_eg5saEHlDecW)里也提到了这个脚本,他们觉得可能对在线浏览时解除DRM有所帮助,但是我完全看不懂也不会用……
烈之斩 说: 萌享那个贴我看了下没啥下文(至少没人贴出来)。
4chan你搜18、19年的帖子就知道破解方法一直是有人有的(包括新版),包括国内也有很多人会,但是他们不外放而已(原因显而易见)。
其实BW的...
https://gist.github.com/Sg4Dylan ... 0-1-8_2018-02-09-js
然后在一个最近的帖子(http://cncc.bingj.com/cache.aspx ... 5UqM2Q_eg5saEHlDecW)里也提到了这个脚本,他们觉得可能对在线浏览时解除DRM有所帮助,但是我完全看不懂也不会用……
#9-3 - 2019-5-10 10:21
bangumi 教宗
这个脚本的作者是国人,你可以试试给他发邮件(
邮箱地址在他的GitHub首页
WindowsNeptune 说: 刚在外网搜的时候找到一个相关的脚本:
https://gist.github.com/Sg4Dylan ... 0-1-8_2018-02-09-js
然后在一个最近的帖子...
邮箱地址在他的GitHub首页
#9-4 - 2019-5-11 06:15
#9-5 - 2019-5-11 06:30
烈之斩
第二个地址打不开…
第一个看了下,难道不是BW在线浏览器的js而已?
https://preview.bookwalker.com.t ... 2.0.5_2018-09-28.js
12w行就是有改动也找不到在哪里了
WindowsNeptune 说: 刚在外网搜的时候找到一个相关的脚本:
https://gist.github.com/Sg4Dylan ... 0-1-8_2018-02-09-js
然后在一个最近的帖子...
第一个看了下,难道不是BW在线浏览器的js而已?
https://preview.bookwalker.com.t ... 2.0.5_2018-09-28.js
12w行就是有改动也找不到在哪里了
#10 - 2019-5-10 17:14

#13 - 2019-5-26 16:54
#15 - 2019-6-7 11:30
CureDovahkinn
(プリキュアになりたい)
#15-2 - 2019-6-8 12:49
CureDovahkinn
记得有个ai项目是根据效果图直接生成html,自动切图也可以有啊!
烈之斩 说: 按键精灵截图+ocr没什么难度,本来BW客户端对截图就毫无限制的
想要的是完整提取原始文件(尤其是图片)罢了。
#16 - 2019-6-17 19:36
風林火山
#16-2 - 2019-7-12 13:13
烈之斩
轻小说Kindle的HD图源(res提取)也比BW差点好像,大多提取出来只有1600px
杂志之类的倒是画质差不多(分辨率的话kindle都是1920px,BW好像是2048)
Aeroblast 说: 仅就轻小说而言,亚马逊的高清图源是分开放的,需要额外处理。虽然对比的样本很少,我猜质量应该是一样的。
杂志之类的倒是画质差不多(分辨率的话kindle都是1920px,BW好像是2048)
#16-3 - 2019-7-12 13:57
Aeroblast
我最近买的几本以及看别人提取res的都是2048高的;而老书很多1600,对比过去同期同样的BW书是2048(只找到过一本)。所以我推测是在某个时间点以后上架的书是和BW一样质量的。
烈之斩 说: 轻小说Kindle的HD图源(res提取)也比BW差点好像,大多提取出来只有1600px
杂志之类的倒是画质差不多(分辨率的话kindle都是1920px,BW好像是2048)
#16-4 - 2019-7-12 14:38
烈之斩
如果现在也有2048那再好不过
我手头最近的一本是 変態王子と笑わない猫。11 (MF文庫J) 还是1600px
(不过看了下都是16年的了囧)
Aeroblast 说: 我最近买的几本以及看别人提取res的都是2048高的;而老书很多1600,对比过去同期同样的BW书是2048(只找到过一本)。所以我推测是在某个时间点以后上架的书是和BW一样质量的。
我手头最近的一本是 変態王子と笑わない猫。11 (MF文庫J) 还是1600px
(不过看了下都是16年的了囧)
#16-5 - 2020-8-6 11:21
ef和辣石请艾特devil233
看了下手上的kindle漫画都还是1920,看来只有日轻同步了。。。不过看最后有一张bw的logo,按理说是同一图源
Aeroblast 说: 我最近买的几本以及看别人提取res的都是2048高的;而老书很多1600,对比过去同期同样的BW书是2048(只找到过一本)。所以我推测是在某个时间点以后上架的书是和BW一样质量的。
#16-6 - 2020-9-21 19:54
風林火山
漫画基本没啥区别,除了部分独占喝搞活动bw几乎没有什么优势
编辑ef和辣石请@编辑ef和辣石请@devil233 说: 看了下手上的kindle漫画都还是1920,看来只有日轻同步了。。。不过看最后有一张bw的logo,按理说是同一图源
#16-7 - 2020-9-24 15:48
#18 - 2019-7-15 11:52
Tandy1000

#18-2 - 2019-7-17 10:21
Aeroblast
网页版都是把图片解密绘制到canvas,所以下载资源是这种加密的,不只是BW这么做。如果只需要图片,可以试试在写入canvas前截取到写入的部分。
(另外CanvasRenderingContext2D.getImageData()貌似会因为浏览器安全策略被挡,而且也不知道是不是返回写入的原始数据)
(另外CanvasRenderingContext2D.getImageData()貌似会因为浏览器安全策略被挡,而且也不知道是不是返回写入的原始数据)
#18-4 - 2019-7-17 16:09
Tandy1000
额,我用的是官网下载的最新版Chrome,系统是Win10,直接加载的那个插件,登陆台湾版BookWalker,在线阅读我买过的漫画,每翻一页他那entries就多一两个
烈之斩 说: 为什么我连检测到下载都不行,一直是0 entries
#18-5 - 2019-7-17 17:35
烈之斩
哦 可能preview不行
WindowsNeptune 说: 额,我用的是官网下载的最新版Chrome,系统是Win10,直接加载的那个插件,登陆台湾版BookWalker,在线阅读我买过的漫画,每翻一页他那entries就多一两个
#18-7 - 2019-7-25 22:35
SgDylan
这个打乱的马赛克在 64x64 分割的时候手搓解密过一次,现在的代码混淆后太长了搞不动
流哲不哼太 说: 下载的话本来就很容易下载,破解了右键限制或者直接F12都能提取,但这就是经过BW加密后的图片,分割成多块根据加密算法改变排列了。
#18-8 - 2019-7-26 08:50
Tandy1000
您好大佬,想麻烦请教一下,是说在线阅读买过的小说的时候看的正文是没有加密的吗?那样的话是否有办法可以复制文本呢?非常感谢
SgDylan 说: 插图建议直接用 Chrome DevTools 虚拟分辨率截图,文本内容记得是冇得加密的
#18-9 - 2019-9-23 02:08
橘枳橼
getImageData 是在防 fingerprinting 还是 cross-origin 内容?多半不是原始数据,只要有变换甚至像素没对齐就是渲染结果了,甚至可能会因为硬件的不同而不同
原始数据的话考虑重写整个 canvas API,但不清楚是否有检测
但如果是混淆的话普遍使用 eval 肯定不会预先留存原生 API
Aeroblast 说: 网页版都是把图片解密绘制到canvas,所以下载资源是这种加密的,不只是BW这么做。如果只需要图片,可以试试在写入canvas前截取到写入的部分。
(另外CanvasRenderingContext2...
原始数据的话考虑重写整个 canvas API,但不清楚是否有检测
但如果是混淆的话普遍使用 eval 肯定不会预先留存原生 API

#22 - 2019-7-24 08:56

#25 - 2019-11-10 11:48
流哲不哼太
(什么都看,什么都不懂)
#25-1 - 2019-11-10 12:40
烈之斩
如果下载的加密epub原生的jpeg就是和网页版一样混淆的图片的话,那其实并没有多少意义了…怎么都得二次保存,并不存在“无损”提取的办法
网页端稍微注入下脚本至少可以获取到原图尺寸的canvas 然后保存就是了
(还没研究怎么批量就是…)
网页端稍微注入下脚本至少可以获取到原图尺寸的canvas 然后保存就是了
(还没研究怎么批量就是…)
#25-2 - 2019-11-15 21:45
某兎
客户端的都是原图,只是混淆了字节,没有混淆图片
网页端的话我是一页页翻的
NFBR.a6G.Initializer.B0U.menu.model.get("viewerPage")
NFBR.a6G.Initializer.B0U.menu.a6l.moveToPage()
另外有没有研究过Android端的dalao能说说怎么过它的root检测,连Magisk都不行
完事了,PC端licenseUnitVersion还在5,Android端却跑到6了,而且Android竟然还保留着3-5的文件名映射 (虽然低版本的文件还是会提示版本不符)
另外某处拿"島風雪風吹雪赤城"来当passPhrase太草了
烈之斩 说: 如果下载的加密epub原生的jpeg就是和网页版一样混淆的图片的话,那其实并没有多少意义了…怎么都得二次保存,并不存在“无损”提取的办法
网页端稍微注入下脚本至少可以获取到原图尺寸的canvas 然...
网页端的话我是一页页翻的
NFBR.a6G.Initializer.B0U.menu.model.get("viewerPage")
NFBR.a6G.Initializer.B0U.menu.a6l.moveToPage()
另外有没有研究过Android端的dalao能说说怎么过它的root检测,连Magisk都不行
完事了,PC端licenseUnitVersion还在5,Android端却跑到6了,而且Android竟然还保留着3-5的文件名映射 (虽然低版本的文件还是会提示版本不符
)另外某处拿"島風雪風吹雪赤城"来当passPhrase太草了
#25-3 - 2019-11-15 22:15
流哲不哼太
找个较旧的版本,然后自己写个xp插件之类的屏蔽掉root检测跟自动更新之类的(
某兎 说: 客户端的都是原图,只是混淆了字节,没有混淆图片
网页端的话我是一页页翻的
NFBR.a6G.Initializer.B0U.menu.model.get("viewerPage")
NFBR.a6G....
#25-4 - 2019-11-16 17:23
烈之斩
多谢。
能再多问句canvas自动下载怎么绕过“Tainted canvases may not be exported”的问题么?
我因为很少整本下载,所以一般就手动保存了,不过多少还是繁琐…
某兎 说: 客户端的都是原图,只是混淆了字节,没有混淆图片
网页端的话我是一页页翻的
NFBR.a6G.Initializer.B0U.menu.model.get("viewerPage")
NFBR.a6G....
能再多问句canvas自动下载怎么绕过“Tainted canvases may not be exported”的问题么?
我因为很少整本下载,所以一般就手动保存了,不过多少还是繁琐…
#25-5 - 2019-12-23 17:16
烈之斩
chrome disable-web-security对tainted canvases好像没用,不过还好只出现在magazinewalker上(BW是同域)
某兎 说: 这
是
一
个
竖
条
#25-6 - 2019-12-25 00:14
烈之斩
应该说 disable-web-security这个选项似乎都没用了,加不加在 chrome://version 都看不到
Edit: 去chromium bug tracker搜了半天才知道,原来这个选项必须要和--user-data-dir一起用……也没个提示
----
不过还是请问原档是指?magazinewalker网页版,似乎资源只有打乱的图,是指用App能直接获取到原始图像文件吗?能详细说说吗
某兎 说: 我这边没问题 magazinewalker和DMM都是这样绕过去的
另外magazinewalker的原档加密比起BW本家弱太多,很容易就能捣鼓出来直接提取原档吧
Edit: 去chromium bug tracker搜了半天才知道,原来这个选项必须要和--user-data-dir一起用……也没个提示
----
不过还是请问原档是指?magazinewalker网页版,似乎资源只有打乱的图,是指用App能直接获取到原始图像文件吗?能详细说说吗
#28 - 2020-2-19 07:01
Yuki Yuuki
#28-2 - 2020-2-19 13:50
Tandy1000
您好大佬,请问是否能指教一下这个大概是如何使用的?从没用过node.js的小白表示非常感谢。
另:请问图片的分辨率是1448*2048左右吗?另图片属性中是否有编辑信息(如Photoshop 版本等),如果有的话那就应该是真的原图。。
另:请问图片的分辨率是1448*2048左右吗?另图片属性中是否有编辑信息(如Photoshop 版本等),如果有的话那就应该是真的原图。。
#28-3 - 2020-2-19 22:26
Yuki Yuuki
分辨率确实是1448*2048.这张样本就是我下载两张图片随手写脚本合成的:http://tiebapic.baidu.com/forum/ ... 91b9d16fdfa6008.jpg
WindowsNeptune 说: 您好大佬,请问是否能指教一下这个大概是如何使用的?从没用过node.js的小白表示非常感谢。
另:请问图片的分辨率是1448*2048左右吗?另图片属性中是否有编辑信息(如Photoshop 版本等...
#28-4 - 2020-2-19 22:28
Yuki Yuuki
假设你们用windows系统的话,随手百度来的结果:https://www.jianshu.com/p/c5575c8351f6
流哲不哼太 说: 请教大佬,这个npm模块如何安装使用?
#28-5 - 2020-2-21 21:29
某兎
保存出来是png就基本可以确认不是原图了,一般这种电子书都只会给你jpeg。看了下代码就是仿网页版viewer操作去切割拼合那块乱图。要是官方update一下数据解密和拼合流程,又得跟着更新,还不如整个脚本直接去官方viewer抓图算了。
PS:补充一组对比 https://share.dmca.gripe/a/F1rYLot0
PS:补充一组对比 https://share.dmca.gripe/a/F1rYLot0
#28-6 - 2020-2-29 14:00
#40 - 2020-8-4 16:01
ef和辣石请艾特devil233
(mwb,节省双方时间不谢)
#40-2 - 2020-8-6 16:22
ef和辣石请艾特devil233
https://www.tsdm39.net/forum.php ... p;extra=&page=4
或
https://github.com/Aeroblast/UnpackKindleS
老资源珂以去kobo,而且这平台的破解已经到处都是。
Yukimaru 说: 看楼上说kindle的高清源要分开提取,该怎么搞呢?
以及也是看楼上说老资源还是低清图源
或
https://github.com/Aeroblast/UnpackKindleS
老资源珂以去kobo,而且这平台的破解已经到处都是。
#40-3 - 2020-9-1 20:17
searock
乐天注册不了,大陆手机收不到验证码
编辑ef和辣石请@编辑ef和辣石请@devil233 说: https://www.tsdm39.net/forum.php ... p;extra=&page=4
或
https://github.com/Aeroblast/UnpackKindle...
#40-5 - 2020-9-3 19:17
searock
kobo确实不需要手机,不过能不能指条路,比如yahoo注册新账号要日本手机
编辑ef和辣石请@编辑ef和辣石请@devil233 说: 途径多了去了,不能大陆手机注册的国外网站软件又不是就乐天
#45 - 2021-12-1 23:51
#49 - 2024-11-17 03:57
#54 - 2025-9-25 00:59
yyfll
(本质KY,跳过别看)
#54-1 - 2025-9-27 01:02
qtry
kobo确实简单,但kobo存在压图的问题,据萌享那边的人测试图片超过1.45m会压图,尤其是尖端的书最为严重,他家电子书体积很大,所以对比其他平台体积相差会大一点,压图过的图片也会糊一点,这个规律也适用于日版
#54-2 - 2025-9-27 04:11
yyfll
大图我还没碰到过,还有这种问题的
qtry 说: kobo确实简单,但kobo存在压图的问题,据萌享那边的人测试图片超过1.45m会压图,尤其是尖端的书最为严重,他家电子书体积很大,所以对比其他平台体积相差会大一点,压图过的图片也会糊一点,这个规律也...
#54-3 - 2025-9-27 23:45
谷
Kobo和BW我之前专门拿JPEGsnoop看过,亮度的质量因子 kobo 83.88 bw 90.06 然后色度的质量因子 kobo 89.11 bw 89.93,对比了好几部不管图片大小都是这个数值,还有个区别就是部分漫画位深kobo是24位bw是32位,不过就算有数值差别但反正我用一般的看图软件放300%都看不出啥区别,只有丢PS里逐个像素看才能看出明显区别
qtry 说: kobo确实简单,但kobo存在压图的问题,据萌享那边的人测试图片超过1.45m会压图,尤其是尖端的书最为严重,他家电子书体积很大,所以对比其他平台体积相差会大一点,压图过的图片也会糊一点,这个规律也...
#54-4 - 2025-9-27 23:49
#54-5 - 2025-9-28 01:19
yyfll
先前只是抓了两下试试看,还真没注意到这点。
这个项目对BW似乎是对Canvas API进行操作,直接拿到绘制的图像的,并不是单纯的截图。我对这方面不是很了解,具体是否会受窗口分辨率影响,不是太好说)但是以我手头的几本书来看,BWJP这边都获取到了正确分辨率的图像,对比原图跑出来SSIM为0.99388,PSNR为46.22。
尤其考虑到我的显示器根本没有1920的高度,基本可以否定吧。
发来的混淆后的瓦片图记得应该是JPEG格式,这意味着在混淆后还有一次不可避免的有损编码的过程,这应该就是PSNR和SSIM未能达到原图的原因。
意味着破解网页端其实是拿不到真正实际意义的“原图”,但属于非常接近的源了。
从Canvas拿到拼好的图,使用PNG无损保存,这样也是不错的,破解门槛低,也不受加密算法变化的影响。
空谷枫 说: 你说的那个GitHub项目我感觉还是类似于截图之类的操作,因为下载下来的图片分辨率会根据我浏览器窗口大小变化而变化,但或许整个4K屏下的就是原图了?
这个项目对BW似乎是对Canvas API进行操作,直接拿到绘制的图像的,并不是单纯的截图。我对这方面不是很了解,具体是否会受窗口分辨率影响,不是太好说)但是以我手头的几本书来看,BWJP这边都获取到了正确分辨率的图像,对比原图跑出来SSIM为0.99388,PSNR为46.22。
尤其考虑到我的显示器根本没有1920的高度,基本可以否定吧。
发来的混淆后的瓦片图记得应该是JPEG格式,这意味着在混淆后还有一次不可避免的有损编码的过程,这应该就是PSNR和SSIM未能达到原图的原因。
意味着破解网页端其实是拿不到真正实际意义的“原图”,但属于非常接近的源了。
从Canvas拿到拼好的图,使用PNG无损保存,这样也是不错的,破解门槛低,也不受加密算法变化的影响。
#54-7 - 2025-9-28 13:24
yyfll
补充:固定レイアウトのタイプ选择ノーマル就是整本下了,非常抱歉错怪BW了
选择ハイスピードデータ就可以解锁超慢的一张张爬拉。
可以尝试用自己生成的RSA私钥对应的公钥,替换掉发送给BW服务器的公钥,以此避开必须从客户端的SQLite中拿私钥的操作。
选择ハイスピードデータ就可以解锁超慢的一张张爬拉。
可以尝试用自己生成的RSA私钥对应的公钥,替换掉发送给BW服务器的公钥,以此避开必须从客户端的SQLite中拿私钥的操作。
#54-8 - 2025-10-1 03:09
qtry
这些数据我是不太懂,但是呢有差异的图片一个yuv444,一个yuv420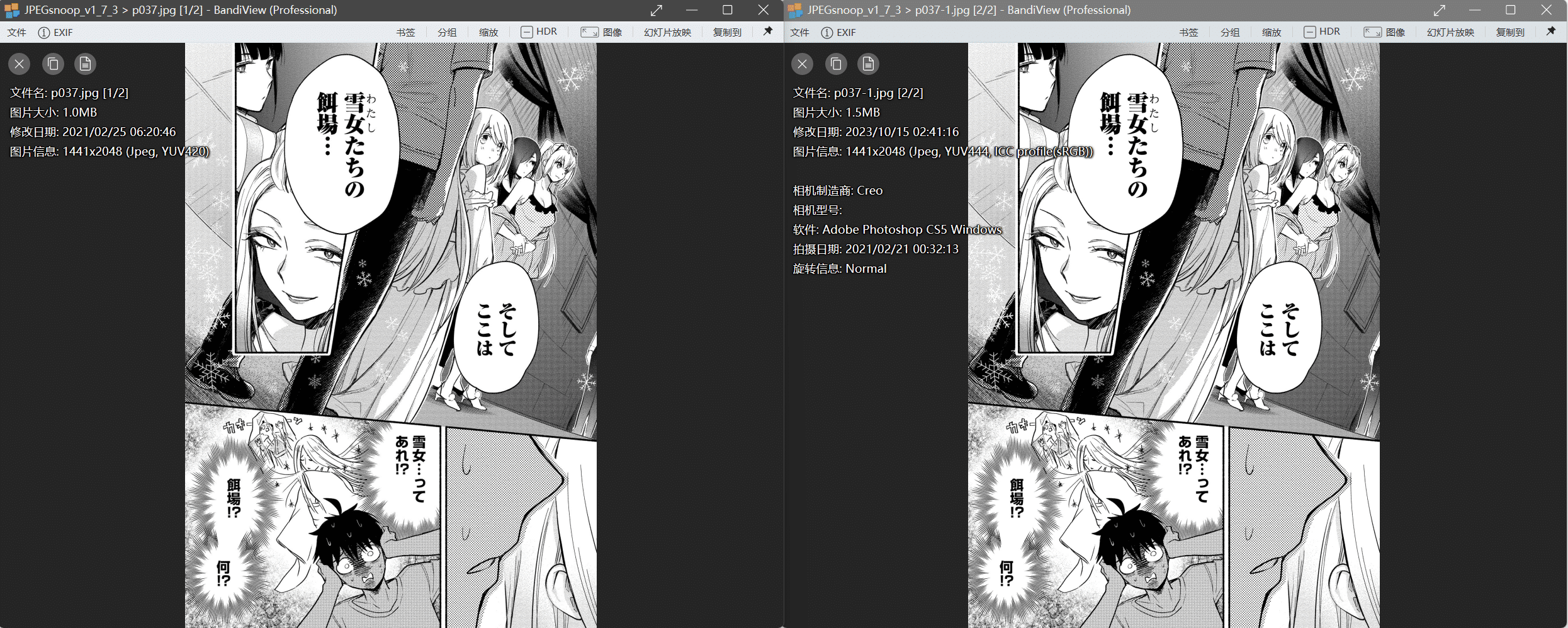
除去这些差异的图片之外,其他都是一模一样的,就算说是每个平台可能有着不一样的参数设定(理论上来说各个平台拿到的档案都是一样的,除了日亚他锁死分辨率宽高各为1920),也不可能说会针对某张图片进行处理的,都会是全部处理的,所以这个就是压图了
下载连载
有兴趣可以下载来对比一下,比如p037,p049,p083这几张
单纯看的话确实说是看不出区别,从收藏角度来讲我还是选择bw的
空谷枫 说: Kobo和BW我之前专门拿JPEGsnoop看过,亮度的质量因子 kobo 83.88 bw 90.06 然后色度的质量因子 kobo 89.11 bw 89.93,对比了好几部不管图片大小都是这个数...
除去这些差异的图片之外,其他都是一模一样的,就算说是每个平台可能有着不一样的参数设定(理论上来说各个平台拿到的档案都是一样的,除了日亚他锁死分辨率宽高各为1920),也不可能说会针对某张图片进行处理的,都会是全部处理的,所以这个就是压图了
下载连载
有兴趣可以下载来对比一下,比如p037,p049,p083这几张
单纯看的话确实说是看不出区别,从收藏角度来讲我还是选择bw的
#54-9 - 2025-10-1 04:10
yyfll
我也找了一本来,确实Kobo是没有超过1,500,000字节的图像的,所以准确来说阈值应该是1.43MiB左右)。
他说的是这个,通过量化表反推得到的JPEG压缩质量设置情况,大多看图软件应该都有。
可以看到原图一般都是Q93这样,BOOK WALKER网页阅览器二压为Q90,而Kobo二压给了个Q81 + 下采样。
如IrfanView显示为
JPEGsnoop显示为
qtry 说: 这些数据我是不太懂,但是呢有差异的图片一个yuv444,一个yuv420
除去这些差异的图片之外,其他都是一模一样的,就算说是每个平台可能有着不一样的参数设定(理论上来说各个平台拿到的档案都是一样的,...
他说的是这个,通过量化表反推得到的JPEG压缩质量设置情况,大多看图软件应该都有。
可以看到原图一般都是Q93这样,BOOK WALKER网页阅览器二压为Q90,而Kobo二压给了个Q81 + 下采样。
如IrfanView显示为
JPEG, quality: 81, subsampling ON (2x2)
JPEGsnoop显示为
*** Marker: DQT (xFFDB) ***
Define a Quantization Table.
OFFSET: 0x00000014
Table length = 67
----
Precision=8 bits
Destination ID=0 (Luminance)
Approx quality factor = 81.19 (scaling=37.62 variance=1.08)
*** Marker: DQT (xFFDB) ***
Define a Quantization Table.
OFFSET: 0x00000059
Table length = 67
----
Precision=8 bits
Destination ID=1 (Chrominance)
Approx quality factor = 81.26 (scaling=37.48 variance=0.21)

#58 - 2026-4-5 09:36
yyfll
(本质KY,跳过别看)
#58-2 - 2026-4-10 10:13
yyfll
之前有人已经做过日本站和国际站的了。
我自己这几天也搓了一个,有点糙Renta_downloader
dfdfdfdf 说: 乱搭的提取能实现成工具化吗,renta上也买了些书,但一直没法提取,有小说也有漫画的。
我自己这几天也搓了一个,有点糙Renta_downloader
#58-3 - 2026-5-10 17:38
dfdfdfdf
话说还有一个网站cmoa.jp。 也能搞吗?
里面有些书是其他网站都很难找到,比如https://www.cmoa.jp/title/187991/
yyfll 说: 之前有人已经做过日本站和国际站的了。
我自己这几天也搓了一个,有点糙Renta_downloader
里面有些书是其他网站都很难找到,比如https://www.cmoa.jp/title/187991/
#58-4 - 2026-5-11 03:29
yyfll
cmoa之前看过,没见过这么坑的网站。分析到它的时候我怒骂了一通。
它假装自己是电子书站点,实际上你下载的内容是和Web端一样的SpeedBinB拼图,而不是ePub之类电子书,只是数据缓存到本地了而已
也就是说拿到手的不是原图,是特么的SpeedBinB切分打乱后的二次压缩图像。
这种二次压缩也能接受的话,cmoa也没有别的加密,东西直接就是裸的,找SpeedBinB解析的项目,把拼图拼回来就行了,没了。
这种站点我很讨厌,自然也没搓过啥出来。
dfdfdfdf 说: 话说还有一个网站cmoa.jp。 也能搞吗?
里面有些书是其他网站都很难找到,比如https://www.cmoa.jp/title/187991/
它假装自己是电子书站点,实际上你下载的内容是和Web端一样的SpeedBinB拼图,而不是ePub之类电子书,只是数据缓存到本地了而已
也就是说拿到手的不是原图,是特么的SpeedBinB切分打乱后的二次压缩图像。
这种二次压缩也能接受的话,cmoa也没有别的加密,东西直接就是裸的,找SpeedBinB解析的项目,把拼图拼回来就行了,没了。
这种站点我很讨厌,自然也没搓过啥出来。

